
Baru-baru ini,
istilah Big Data telah diciptakan mengacu pada tantangan dan keuntungan yang
diperoleh dari pengumpulan dan pemrosesan sejumlah besar data (V. Marx.
Tantangan besar data besar. Nature, 498 (7453): 255-260, 2013). Topik ini telah
muncul sejak organisasi harus berurusan dengan pengumpulan data skala petabyte.
Faktanya, dalam dua tahun terakhir kami telah menghasilkan 90% dari total data yang
dihasilkan dalam sejarah (X. Wu, X. Zhu, G.-Q. Wu, dan W. Ding. Penambangan
data dengan data besar. IEEE Trans. Knowl. Data Eng., 26 (1): 97-107, 2014).
Sumber informasi dalam jumlah sangat besar adalah aplikasi yang mengumpulkan
data dari aliran klik, riwayat transaksi, sensor, dan tempat lain. Namun,
masalah pertama untuk definisi yang benar dari "Big Data" adalah nama
itu sendiri (T. Kraska. Menemukan jarum dalam tumpukan jerami sistem data
besar. IEEE Internet Comput., 17 (1): 84-86, 2013), karena kita mungkin
berpikir bahwa itu hanya terkait dengan Volume data.
Struktur
heterogen, dimensi yang beragam, dan Variasi dari representasi data, juga
memiliki arti penting dalam masalah ini. Coba pikirkan tentang
aplikasi-aplikasi terdahulu yang melakukan perekaman data: implementasi
perangkat lunak yang berbeda akan mengarah pada skema dan protokol yang berbeda
(T. Schlieski dan BD Johnson. Hiburan di zaman data besar. Prosiding IEEE, 100
(Centennial-Issue): 1404-1408, 2012).
Tentu saja itu
juga tergantung pada waktu komputasi, yaitu efisiensi dan Kecepatan dalam
menerima dan memproses data. Pengguna saat ini menuntut "waktu berlalu
yang dapat ditoleransi" untuk menerima jawaban. Kita harus meletakkan
istilah ini dalam kaitannya dengan sumber daya komputasi yang tersedia, karena
kita tidak dapat membandingkan kekuatan komputer pribadi sehubungan dengan
server komputasi perusahaan besar (S. Madden. Dari basis data ke data besar.
IEEE Internet Comput., 16 (3): 4-6, 2012 ).
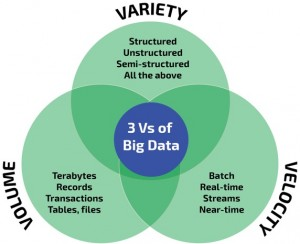
Semua fakta ini
dikenal sebagai 3V tentang Big Data (Gambar 1), yang mengarah pada definisi
yang diberikan oleh Steve Todd di Berkeley University:
Big data adalah
ketika aplikasi normal teknologi saat ini tidak memungkinkan pengguna untuk
mendapatkan jawaban yang tepat waktu, hemat biaya, dan berkualitas untuk
pertanyaan yang didorong data.
Kita harus
menunjukkan bahwa definisi tambahan termasuk hingga 9V dapat ditemukan,
menambahkan istilah seperti Veracity, Value, Viability, dan Visualisasi, antara
lain ( PC Zikopoulos, C. Eaton, D. deRoos, T. Deutsch, dan G. Lapis Memahami
Big Data - Analisis untuk Hadoop dan Streaming Data Kelas Perusahaan.
McGraw-Hill Osborne Media, edisi pertama, 2011).
Tantangan utama
saat menangani Big Data dikaitkan dengan dua fitur utama (A. Labrinidis dan HV
Jagadish. Tantangan dan peluang dengan data besar. PVLDB, 5 (12): 2032-2033,
2012):
Penyimpanan dan
pengelolaan informasi dalam volume besar. Masalah ini terkait dengan DBMS, dan
model hubungan entitas tradisional. Sistem komersial melaporkan skala yang
baik, mampu menangani database multi-petabyte, tetapi selain "biaya"
dalam hal harga dan sumber daya perangkat keras, mereka memiliki kendala
mengimpor data ke representasi asli. Di sisi lain, sistem open source yang
diadopsi secara luas, seperti MySQL, jauh lebih terbatas dalam hal skalabilitas
daripada rekan analitik komersial mereka.
Proses untuk
melakukan eksplorasi volume data yang besar ini, yang bermaksud untuk menemukan
informasi dan pengetahuan yang berguna untuk tindakan di masa depan (X. Wu, X.
Zhu, G.-Q. Wu, dan W. Ding. Data mining dengan besar data. IEEE Trans. Knowl. Data
Eng., 26 (1): 97-107, 2014). Pemrosesan analitis standar dipandu oleh skema
hubungan entitas, dari mana pertanyaan dirumuskan menggunakan bahasa SQL.
Halangan pertama dari jenis sistem ini adalah perlunya melakukan prapembuatan
data, seperti yang dinyatakan sebelumnya. Selain itu, tidak ada banyak dukungan
untuk statistik dan pemodelan di-database, dan banyak programmer DM mungkin
tidak nyaman dengan gaya deklaratif SQL. Bahkan dalam hal mesin menyediakan
fungsionalitas ini, karena algoritma iteratif tidak mudah diungkapkan sebagai
operasi paralel dalam SQL, mereka tidak bekerja dengan baik untuk sejumlah besar
data.
Singkatnya, ada
beberapa kondisi yang harus dipertimbangkan untuk mempertimbangkan masalah
dalam kerangka Big Data. Pertama-tama, dan merujuk pada properti 3V, ambang
batas untuk jumlah informasi yang sedang diproses, dan batasan waktu untuk
memberikan jawaban, harus ditetapkan. Kedua konsep ini juga terkait erat.
Misalnya, jika kita menangani aplikasi pengenalan sidik jari, ada batasan
jumlah sidik jari yang dapat kita kelola dalam database untuk memberikan
jawaban yang akurat dalam waktu singkat, yaitu sepersepuluh detik atau beberapa
detik.
Tetapi,
bagaimana kita menetapkan batas ini? Jawabannya tidak jelas seperti apa yang
"besar" tahun lalu, sekarang dapat dianggap sebagai
"kecil". Oleh karena itu, untuk definisi Big Data yang jelas, kita
juga harus memasukkan teknologi mana yang diperlukan untuk menyelesaikan
masalah. Misalkan perusahaan penjualan utama, yang bertujuan untuk menyesuaikan
harga satuan untuk koleksi barang berdasarkan permintaan dan inventaris. Jelas,
perusahaan ini akan membutuhkan teknologi komputasi di luar kelompok mesin
standar dengan basis data relasional dan produk analisis bisnis yang umum.
Sekarang, jika kami mempertimbangkan proyek ambisi serupa dalam domain
perusahaan pengecer, aplikasi dapat dengan mudah diselesaikan menggunakan
database yang ada dan alat ETL. Yang terakhir tidak dapat dikategorikan sebagai
proyek Big Data, sesuai dengan definisi kami.
Akhirnya, Big
Data adalah tentang wawasan yang ingin kami ekstrak dari informasi. Ada banyak
aplikasi terkenal yang berbasis Cloud Computing seperti server email (Gmail),
media sosial (Twitter), atau berbagi penyimpanan dan cadangan (Dropbox). Semua
perangkat lunak ini mengelola volume data yang tinggi, di mana respons cepat
sangat penting, dan dengan informasi datang pada tingkat tinggi dengan cara
terstruktur atau terstruktur. Mereka juga harus menghadapi kebenaran dalam
informasi; namun, mereka tidak dianggap sebagai Big Data.
Kuncinya di sini
adalah analisis yang dibuat untuk tujuan pengetahuan dan bisnis, yang dikenal
sebagai Ilmu Data (F. Provost dan T. Fawcett. Ilmu Data untuk Bisnis. Apa yang
perlu Anda ketahui tentang penambangan data dan pemikiran analitik data. O
'Reilly Media, edisi 1, 2013). Spesialisasi ini mencakup beberapa bidang
seperti statistik, pembelajaran mesin, DM, kecerdasan buatan, dan visualisasi,
antara lain. Oleh karena itu, Big Data dan Ilmu Data adalah dua istilah dengan
sinergi yang tinggi di antara mereka (MA Waller, SE Fawcett. Ilmu data,
analisis prediktif, dan data besar: sebuah revolusi yang akan mengubah desain
dan manajemen rantai pasokan. J Bus Logistics 2013, 34: 77-84). Beberapa contoh
terkenal termasuk e-Sciences dan disiplin ilmu terkait lainnya (fisika
partikel, bioinformatika, kedokteran atau genomik) Komputasi Sosial (analisis
jejaring sosial, komunitas daring atau sistem pemberi rekomendasi), dan
e-commerce skala besar, yang kesemuanya adalah khususnya data-intensif.
Kata "Big
data" berlaku pada tahun 2017, dan itu akan tetap berlaku di tahun-tahun
berikutnya. Dalam posting kami sebelumnya, saya telah memperkenalkan beberapa
konsep tentang big data, pembelajaran mesin, dan penambangan data (lihat
posting: Memahami Big data, Penambangan data, dan Pembelajaran Mesin dalam 5
Menit). Sekarang mari kita menggali lebih dalam ke Machine Learning dengan
walk-through singkat dari beberapa algoritma ML yang paling umum digunakan,
tidak ada kode, tidak ada teori abstrak, hanya gambar dan beberapa contoh
bagaimana mereka digunakan.
Daftar algoritma
yang dibahas dalam artikel ini meliputi:
- · Pohon keputusan
- · Hutan acak
- · Regresi logistik
- · Mesin dukungan vektor
- · Bayes Naif
- · k-NearestNeighbor
- · k-means
- · Adaboost
- · Jaringan syaraf
- · Markov
Pohon Keputusan
Klasifikasi
sekumpulan data ke dalam kelompok yang berbeda menggunakan atribut tertentu,
jalankan tes di setiap node, melalui penilaian brach, lebih lanjut membagi data
menjadi dua kelompok yang berbeda, seterusnya dan seterusnya. Tes dilakukan
berdasarkan data yang ada, dan ketika data baru ditambahkan, dapat
diklasifikasikan ke grup yang sesuai
Klasifikasi data
berdasarkan beberapa fitur, setiap kali proses menuju ke langkah berikutnya,
ada cabang penilaian, dan penilaian membagi data menjadi dua, dan proses
berlanjut. Ketika tes dilakukan dengan data yang ada, data baru bisa.
Pertanyaan ini dipelajari oleh data yang ada, ketika ada data baru yang masuk,
komputer dapat mengkategorikan data ke dalam daun kanan.

Hutan Acak
Pilih secara
acak dari data asli, dan bentuk ke dalam himpunan bagian yang berbeda.
Matriks S adalah
data asli, dan berisi baris data 1-N, sedangkan A, B, C adalah fitur, dan C
terakhir merupakan singkatan dari kategori.

Buat himpunan
bagian acak dari S, katakanlah kita mendapat himpunan himpunan bagian M.


Dan kami
mendapatkan M set pohon keputusan dari himpunan bagian ini:
Melempar data
baru ke dalam pohon-pohon ini, kita bisa mendapatkan set hasil M, dan kami
menghitung untuk melihat hasil mana yang paling dalam semua set M, kita bisa
menganggap itu sebagai hasil akhir.

Regresi Logistik
Ketika
probabilitas target prediksi lebih besar dari 0, dan kurang dari atau sama
dengan 1, itu tidak dapat dipenuhi oleh model linier sederhana. Karena ketika
domain definisi tidak dalam tingkat tertentu, rentang akan melebihi interval
yang ditentukan.

Lebih baik kita
pakai model dengan jenis ini.

Jadi bagaimana
kita bisa mendapatkan model ini?
Model ini perlu
memenuhi dua kondisi, "Lebih besar dari atau sama dengan 0",
"Kurang dari atau sama dengan 1"

Dan kami
mengubah formula, kami bisa mendapatkan model regresi logistik:

Dengan menghitung
data asli, kita bisa mendapatkan koefisien yang sesuai.
Dan kami
mendapatkan plot model logistik.
Mendukung Mesin Vektor
Untuk memisahkan
kedua kelas dari hyperplane, pilihan terbaik adalah hyperplane yang
meninggalkan margin maksimum dari kedua kelas. Karena Z2> Z1, jadi yang
hijau lebih baik.

Gunakan
persamaan linear untuk mengekspresikan hyperplane, kelas di atas garis lebih
besar dari atau sama dengan 1, kelas lainnya kurang dari atau sama dengan -1.

Hitung jarak
antara titik ke permukaan dengan menggunakan persamaan dalam grafik:

Jadi kita
mendapatkan ekspresi margin total seperti di bawah ini, tujuannya adalah untuk
memaksimalkan margin, yang perlu kita lakukan adalah untuk meminimalkan
penyebut.

Sebagai contoh,
kami menggunakan 3 poin untuk menemukan hyperplane optimal, menentukan vektor
bobot = (2, 3) - (1, 1)

Dan dapatkan
vektor bobot (a, 2a), gantikan kedua titik ini ke dalam persamaan

Ketika a
dikonfirmasi, hasil menggunakan (a, 2a) adalah vektor dukungan,
Pengganti
persamaan dalam a dan w0 adalah mesin dukungan vektor.
Naif Bayes
Berikut ini
contoh NLP:
Memberikan
sepotong teks, periksa sikap teks itu positif atau negatif.

Untuk
menyelesaikan masalah, kita hanya dapat melihat beberapa kata:

Dan kata-kata
ini, hanya akan mewakili beberapa kata dan jumlah mereka.

Dan pertanyaan
awal adalah: Memberi Anda hukuman, kategori apa yang termasuk dalam kategori
itu?
Dengan
menggunakan Aturan Bayes, itu akan menjadi pertanyaan yang mudah.

Pertanyaannya
menjadi, di kelas ini, berapa probabilitas terjadinya kalimat ini? Dan ingatlah
untuk tidak melupakan dua probabilitas lainnya dalam persamaan.
Contoh:
probabilitas kemunculan kata "cinta" adalah 0,1 di kelas positif, dan
0,001 di kelas negatif.

k-Nearest Neighbor
Ketika datang
datum baru, kategori mana yang memiliki poin paling dekat dengannya, itu milik
kategori mana.
Sebagai contoh:
Untuk membedakan "anjing" dan "kucing", kami menilai dari
dua fitur, "cakar" dan "suara". Lingkaran dan segitiga
adalah kategori yang diketahui, bagaimana dengan "bintang":

Ketika K = 3,
ketiga garis ini menghubungkan 3 titik terdekat, dan lingkaran lebih banyak,
jadi "bintang" milik "kucing".

k-means
Pisahkan data
menjadi 3 kelas, bagian merah muda adalah yang terbesar, sedangkan yang kuning
adalah yang terkecil.
Pilih 3, 2, 1
sebagai default, dan hitung jarak antara data lainnya dan default, dan
klasifikasikan ke dalam kelas yang memiliki jarak terdekat.

Setelah
klasifikasi, hitung rata-rata setiap kelas, dan atur sebagai pusat baru.

Setelah beberapa
putaran, kita bisa berhenti ketika kelas tidak lagi berubah.

Adaboost
Adaboost adalah
salah satu tolok ukur peningkatan.
Meningkatkan
adalah untuk mengumpulkan pengklasifikasi yang tidak memiliki hasil yang
memuaskan, dan menghasilkan pengklasifikasi yang mungkin memiliki efek yang
lebih baik.

Seperti ditunjukkan
di bawah ini, pohon 1 dan pohon 2 tidak memiliki efek yang baik secara
individual, tetapi jika kami memasukkan data yang sama, dan merangkum hasilnya,
hasil akhir akan lebih meyakinkan.

Contoh untuk
adaboost, dalam pengenalan tulisan tangan, panel dapat mengekstraksi banyak
fitur, seperti arah awal, jarak antara titik awal dan titik akhir, dan
lain-lain.
Saat melatih
mesin, ia akan mendapatkan bobot masing-masing fitur, seperti 2 dan 3, awal
penulisan mereka sangat mirip, jadi fitur ini tidak banyak melakukan
klasifikasi, sehingga bobotnya kecil.

Tetapi sudut
alfa ini memiliki kemampuan yang dapat dikenali, sehingga bobot fitur ini akan
menjadi besar. Hasil akhir akan menjadi hasil dari mempertimbangkan semua fitur
ini.

Jaringan Saraf Tiruan
Di NN, input
mungkin berakhir menjadi setidaknya dua kelas.
Jaringan saraf
terbentuk dari neure, dan koneksi neure.
Lapisan pertama
adalah lapisan masukan, dan lapisan terakhir adalah lapisan keluaran.
Dalam lapisan
tersembunyi dan lapisan keluaran, mereka berdua memiliki pengklasifikasi mereka
sendiri.

Ketika input
masuk dalam jaringan, dan sedang diaktifkan, skor yang dihitung akan diteruskan
ke lapisan berikutnya. Skor yang ditunjukkan pada lapisan output adalah skor
untuk setiap kelas. Contoh di bawah ini mendapatkan hasil kelas 1;

input yang sama
diteruskan ke simpul yang berbeda menghasilkan skor yang berbeda, yang karena
di setiap simpul, memiliki bobot dan bias yang berbeda, dan ini adalah
propagasi.
Markov
Markov Chain
terdiri dari status dan transisi.
Misalnya,
dapatkan Rantai Markov berdasarkan "rubah cokelat cepat melompati anjing
malas".
Pertama, kita
perlu mengatur setiap kata di bawah negara, dan kita perlu menghitung
probabilitas transisi negara.

Ini adalah
probabilitas yang dihitung oleh satu kalimat tunggal. Saat Anda menggunakan
data besar teks untuk melatih komputer, Anda akan mendapatkan matriks transisi
status yang lebih besar, seperti kata-kata yang dapat mengikuti
"the", dan probabilitasnya yang sesuai.





Tidak ada komentar:
Posting Komentar